Frozen-Support Medical Image Segmentation vs Trained Networks
A multi-domain data-efficiency study — frozen-foundation-model assembly (an LLM polygon drawer in the deployed path on 1/5 domains, else SAM / op_sam / SegGPT) + a numpy genome, zero gradient training on the target task.
Data-efficiency
The crossover — one panel per domain
Frozen assembly vs the strongest compatible, complete three-seed trained NN at each K, selected from U-Net, SegFormer and nnU-Net only. Filled comparator dot + whisker = exactly seeds 0/1/2 and a 95% df=2 t interval; absent dot = no eligible comparator. Every curve on this page is training-free; the gradient-trained tuned-decoder lane is reported separately in docs/push/gradient_lane_ablation_20260725.md.
▬ best-case pipeline (the per-domain pipeline in the best-case table below; the green points match that table cell-for-cell) · □/■ strongest trained NN
Frozen-support assembly data efficiency (Dice) vs strongest trained NN
| Domain | Pipeline | N=5 | N=10 | N=25 | N=50 |
|---|---|---|---|---|---|
| ISIC | frozen-support genome (leak-clean test) | 0.820vs 0.788 | 0.819vs 0.832 | 0.852vs 0.833 | 0.855vs 0.840 |
| Kvasir | frozen-support op_sam (count-selected supports) | 0.814vs 0.600 | 0.837vs 0.709 | 0.848vs 0.818 | 0.864vs 0.854 |
| Spleen | frozen-support strict-2D (matched-N estimate) | 0.831vs 0.568 | 0.883vs 0.645 | 0.899vs 0.773 | 0.908vs 0.855 |
| Prostate | frozen-support strict-2D (matched-N estimate) | 0.724vs 0.596 | 0.742vs 0.700 | 0.741vs 0.791 | 0.738vs 0.795 |
| CXR | frozen-support SegGPT in-context | 0.936vs 0.918 | 0.937vs 0.927 | 0.938vs 0.930 | 0.948vs 0.946 |
Frozen-support data efficiency — one configured pipeline per domain (the one that surpasses the trained NN in the most budgets); bold = ≥ strongest 3-seed trained NN at that budget (grey “vs” = the strongest compatible trained NN); leak-safe.
pipeline_params.json, which is not the lane that produced the published row — the published row comes from the cons_pb3 lane, certified strict-2D empirically (per-slice isolation, batch permutation and id-blinding bit-identical 28/28 across five budgets, plus a negative control). The separately reported deployed 3D lane did use volume_prior + outlier_multiproto — a different and less strict lane — until 2026-07-25, when both keys were deleted from pipeline_params.json at a measured cost of −0.0897 on the 28-slice test split. That deployed lane is now strict-2D too. Lane switched 2026-07-25: Prostate was correctly relabelled volume-context. Rather than publish a row the trained-NN comparator cannot be fairly compared against, the published row was replaced by the already-measured strict-2D counterpart — same estimator, same 30-slice test split, same ground truth, same 20-slice validation gate fit, with only the cross-slice (traj_reprompt) seed removed. Every pipeline row on this page is now strict-2D, and since 2026-07-25 so is every shipped pipeline_params.json block: traj_reprompt was deleted from the deployed Prostate configuration too (−0.0419 on the deployed lane). This is the one correction that moved numbers, and it moved them down; the superseded volume-context row is shown below rather than discarded. No number on this page changed in that label correction — those green curves are the same measurements; only labels moved. The word collision behind it: “strict-N” in the source artifacts means a strict matched-N label budget, which is a different axis from strict-2D. Prostate superseded volume-context row (what the strict-2D switch gave up): 0.801 / 0.825 / 0.835 / 0.824 at N=5/10/25/50, versus the published strict-2D 0.724 / 0.742 / 0.741 / 0.738. Against the same comparator the superseded row beat the trained NN at N=5, 10, 25, 50 and the published row beats it at N=5, 10. That difference is the cost of the protocol, not a re-measurement: both curves were already cached, nothing was re-run, and the wins at the mid budgets were never apples-to-apples because the trained comparator reads no sibling slices. Full audit: docs/push/prostate_strict2d_verdict_20260725.md. Pre-correction grid preserved verbatim at report/dataeff_grid.pre20260725.json.Every green pipeline curve is frozen-support (no gradient training; frozen models plus numpy skills), matching the best-case table cell-for-cell. Reported budget grid: N≤50 (narrowed 2026-07-25; the measured N=100 cells are retained in results/manifest.json, out of the reported grid rather than removed). ISIC and CXR carry matched 95% image-level bootstrap intervals (10,000 iterations, fixed seed) at N=5/10/25/50. Kvasir carries matched intervals at every reported budget, including the validation-selected count-30 record at N=50. Spleen and Prostate are matched-N (strict label-budget) estimates without matching uncertainty intervals, so their green curves have no whiskers — a budget axis, separate from the protocol axis stated above, on which every row here is strict-2D.
Detailed data-efficiency figure — five settled domains, frozen-support pipelines
results/manifest.json). Green is the frozen-support pipeline curve for every domain (no gradient training; frozen models plus numpy skills), matching the best-case table cell-for-cell. Protocol (settled 2026-07-25): all five panels are strict-2D — no row reads sibling slices of the same test volume. Getting there took two different moves. Prostate was correctly relabelled volume-context (its deployed traj_reprompt stage re-decodes a slice from its siblings), so its published row was switched to the already-cached strict-2D counterpart: same estimator, same test split, same validation gate fit, cross-slice seed removed. That switch lowered the plotted Prostate values by 0.075–0.094 and narrows its lead over the trained NN from N≤50 to N≤10; the superseded row is preserved, not deleted. Spleen, by contrast, was relabelled volume-context the same day and that relabel is retracted — it was read off pipeline_params.json rather than off the cons_pb3 lane that produced the published row, which is certified strict-2D empirically, and no Spleen value moved. Green whiskers are matched per-image intervals: ISIC/CXR at N=5/10/25/50 and Kvasir at all four reported budgets. Spleen and Prostate matched-N (strict label-budget) estimates currently have no matching uncertainty intervals. U-Net, SegFormer and nnU-Net use protocol-compatible cached score artifacts; filled squares and whiskers appear only for exact seeds 0/1/2 and show 95% df=2 t intervals. Historical cached-mask SAM scores are excluded. Label draw (corrected 2026-07-25): every arm in every cell now uses the canonical first-N-sorted draw. Previously the Spleen and Prostate nnU-Net columns alone were patient-stratified, so those cells compared arms trained on different label sets; the matched three-seed artifacts already existed and were substituted without retraining. On the two volumetric organs first-N sees only 2 distinct Spleen patients at N=5 — a real property of the low-budget regime that now applies to every arm equally. Exact values, label counts, seed counts and source paths are in dataeff_grid.json.Open baseline question (2026-07-26) — an independent randomized-draw trained-net grid disputes the CXR best-NN bar
A separately-produced trained-net grid — 3 architectures × 5 domains × 5 random label draws × 3 seeds (15 runs per cell, versus the 3 behind every bar plotted above) — was verified and assembled at results/agenticseg_nnunet_results_full/. Its test splits are byte-identical to the canonical ones for all five domains, it is leak-free at both the image-ID and the patient-volume level, and every cell's mean and median Dice recompute exactly from its per-image scores. Nothing from it has been promoted into any number on this page, in results/manifest.json, or in any paper table; the tables above are unchanged. It is recorded here because on one domain it does not agree.
The comparison is only meaningful at N=25 and N=50 (the independent grid carries U-Net and SegFormer only at those budgets; at N=5/10 it is nnU-Net alone, so no max-over-three bar exists there) and only on ISIC, Kvasir and CXR (on Spleen and Prostate the two label draws span different numbers of patients — as few as 1 versus 5 at Prostate N=5 — so they are not like-for-like). Of those six clean cells, four agree and two flip:
| Cell | published bar | independent bar | Δ | assembly | published | independent |
|---|---|---|---|---|---|---|
| ISIC N=25 | 0.8333 | 0.7640 | −0.0693 | 0.8519 | win | win |
| ISIC N=50 | 0.8405 | 0.8401 | −0.0004 | 0.8550 | win | win |
| Kvasir N=25 | 0.8184 | 0.8215 | +0.0031 | 0.8478 | win | win |
| Kvasir N=50 | 0.8537 | 0.8458 | −0.0079 | 0.8643 | win | win |
| CXR N=25 | 0.9295 | 0.9472 | +0.0177 | 0.9382 | win (+0.0087) | loss (−0.0090) |
| CXR N=50 | 0.9461 | 0.9529 | +0.0068 | 0.9482 | win (+0.0021) | loss (−0.0047) |
The CXR disagreement is not draw noise and is corroborated inside this repository. Two cached CXR baseline families exist: nn_baselines_perimage/ (3 seeds, the family gen_dataeff.py prefers for U-Net/SegFormer) gives U-Net 0.9287 and SegFormer 0.9257 at N=25, while nn_baselines/ (2 seeds, so it never qualifies for a three-seed bar) gives 0.9449 and 0.9477. The independent grid measures 0.9471 and 0.9472 — with a SegFormer standard deviation of 0.0028 across 15 runs — so it lands on the higher family. Because the preferred family is the lower one, the published CXR N=25 bar falls back to nnU-Net at 0.9295 and is understated by roughly 0.018. CXR is exactly the domain where this matters: it carries no patient-clustering confound and has full three-architecture coverage, and its published margins (+0.0087 and +0.0021) are smaller than the discrepancy.
A plausible mechanism is unverifiable from the artifacts: no U-Net or SegFormer cached cell anywhere in this repository records a resize field (274 cells checked; only nnU-Net records resize: 224), and the independent grid records no resolution either. A resize difference between the two families would produce exactly this kind of systematic offset, but nothing on disk can confirm or exclude it.
Machine-readable: report/baseline_corroboration_20260726.json. Bundle, validation and the two confounds: results/agenticseg_nnunet_results_full/README.md. Analysis: docs/push/nnunet_bundle_integration_20260726.md. The page as it stood before this note is cached at report/index.prebaseline_20260726.html. Resolving the CXR bar is an author decision; it would change a published number and is therefore not made here.
Current data-efficiency comparison and N=50 mechanism control
Reported budget grid: N≤50 (narrowed 2026-07-25). The N=100 cells were measured and are retained in full in results/manifest.json — they are out of the reported grid, not removed — but they are no longer tabulated or plotted here. Strongest compatible trained NN per cell — the best complete three-seed result among pretrained U-Net, SegFormer, and from-scratch nnU-Net — compared with the frozen-support assembly. All values come from the same generated grid as the crossover above. Every row is on one protocol: ISIC, Kvasir, CXR, Spleen and Prostate are all strict-2D, so no assembly row reads sibling test slices the trained-NN comparator cannot. Prostate reached that state on 2026-07-25 by switching its published row to the measured cross-slice-free counterpart, which lowered its cells; Spleen reached it by retracting a mistaken relabel, which moved nothing. See the protocol note in the crossover section above, where the superseded Prostate row is shown alongside the published one.
| Domain | best NN N=10 | N=25 | N=50 | frozen-support assembly N=50 |
|---|---|---|---|---|
| ISIC 2018 · dermoscopy | 0.832 | 0.833 | 0.840 | 0.855 |
| Kvasir · endoscopy polyp | 0.709 | 0.818 | 0.854 | 0.864 |
| MSD Spleen · CT | 0.645 | 0.773 | 0.855 | 0.908 |
| MSD Prostate · MRI | 0.700 | 0.791 | 0.795 | 0.738 |
| Chest X-ray · lung | 0.927 | 0.930 | 0.946 | 0.948 |
docs/push/gradient_lane_ablation_20260725.md, because a gradient-trained arm does not belong in this table. Spleen and Prostate use the matched-N (strict label-budget) estimates and have no matching assembly uncertainty intervals; both are strict-2D, the separately reported deployed 3D Spleen lane and the deployed traj_reprompt Prostate lane WERE different and less strict lanes than the rows above, and on 2026-07-25 both were stripped of their cross-slice stages, so every shipped configuration is now strict-2D as well (Spleen −0.0897, Prostate −0.0419; docs/push/strip_volume_context_20260725.md). Exact seed coverage, protocol labels and provenance are in dataeff_grid.json.Latest Prostate experiments — Codex feedback + SegGPT K sweep / SkillOpt
These are sealed follow-up experiments, kept separate from the deployed five-domain table above. The NN-free Codex pilot uses 15 fixed slices; the frozen SegGPT⊕op_sam lane and K sweep use the 30-case prostate benchmark. Results from different protocols are not subtracted from one another.
Codex crop-zoom + SkillOpt feedback loop
| Protocol | n | variant | mean Dice | Δ | paired 95% CI | status |
|---|---|---|---|---|---|---|
| NN-free LLM polygon lane | 15 | frozen baseline | 0.6188 | — | — | reference |
| NN-free LLM polygon lane | 15 | Codex REPAIR + independent JUDGE | 0.6524 | +0.0336 | [+0.0097, +0.0612] | positive pilot |
| Frozen SegGPT⊕op_sam lane | 30 | sealed base cache | 0.7843 | — | — | reference |
| Frozen SegGPT⊕op_sam lane | 30 | crop-zoom SkillOpt + Codex judge | 0.7840 | −0.00027 | [−0.00080, 0.00000] | null; default-off |
| Frozen SegGPT⊕op_sam lane | 30 | full skill-family GT oracle | 0.8302 | +0.0459 | — | headroom only |
| Trained benchmark | 30 | nnU-Net, N=100 (3-seed mean) | 0.8463 | +0.0620 vs sealed base | — | current strongest NN |
Uncapping SegGPT K
We removed the implicit K=min(8,N) ceiling and reran the same full frozen pipeline on the same 30 held-out slices. K is the number of query-retrieved in-context support pairs, not gradient-training set size. Every run reads from the same pool of 100 leak-free TRAIN pairs, stored at 224×224. Raw joint inference fits through K=10 on a 12 GB TITAN Xp; raw K=12 and K=16 OOM. K>10 therefore uses a memory-safe approximation: feature-ensemble chunks of at most 8, followed by a support-count-weighted pixel vote. Two GPUs ran separate values/shards concurrently; they reduced wall time but did not combine VRAM.
| Full frozen pipeline | K | execution | mean Dice | median | Δ vs K=8 | gap to NN |
|---|---|---|---|---|---|---|
| SegGPT gate | 5 | joint | 0.7832 | 0.8433 | −0.0044 | −0.0631 |
| SegGPT gate · deployed | 8 | joint | 0.7877 | 0.8483 | reference | −0.0587 |
| Uncapped SegGPT gate | 10 | joint | 0.7856 | 0.8560 | −0.0021 | −0.0608 |
| Uncapped SegGPT gate | 25 | chunk 8 + weighted vote | 0.7845 | 0.8433 | −0.0032 | −0.0619 |
| Uncapped SegGPT gate · exploratory | 50 | chunk 8 + weighted vote | 0.7988 | 0.8499 | +0.0112 | −0.0475 |
| Uncapped SegGPT gate | 100 (all) | chunk 8 + weighted vote | 0.7798 | 0.8433 | −0.0079 | −0.0666 |
| Per-image best K · GT oracle | 5/8/10/25/50/100 | not deployable | 0.8090 | — | +0.0213 | −0.0374 |
| nnU-Net, N=100 | — | 3-seed mean | 0.8463 | — | +0.0587 | reference |
Sealed K-router SkillOpt transfer test
The K sweep also has a GT-isolated router experiment (seggpt_k_skillopt.py, driven by experiments/seggpt_k_feedback.py). It fits on four validation volumes using leave-one-volume-out SkillOpt, freezes the resulting GT-free router, and then opens the six-volume test labels once for scoring.
| Split / protocol | n | K=8 fallback | frozen SkillOpt | Δ | uncertainty / decisions | verdict |
|---|---|---|---|---|---|---|
| Validation · volume-LOO | 20 / 4 volumes | 0.834094 | 0.840757 | +0.006662 | enable threshold +0.005 | fit enabled |
| Frozen test · volume-cluster bootstrap | 30 / 6 volumes | 0.787672 | 0.769596 | −0.018076 | 95% CI [−0.040310, −0.003187] 2↑ / 4↓ / 24=; P(Δ≤0)=0.9988 | fails transfer |
Segmentation galleries
Per-case GT-vs-prediction overlays for the deployed pipeline on every test image (all 365, sorted worst-Dice first) — open the 5-domain gallery hub → (ISIC · Kvasir · Spleen · Prostate · CXR). Green = ground truth, red = deployed prediction; overlays rendered from the committed mask_cache/.
Where is the wall — the decoder, or localization? A fair few-shot probe
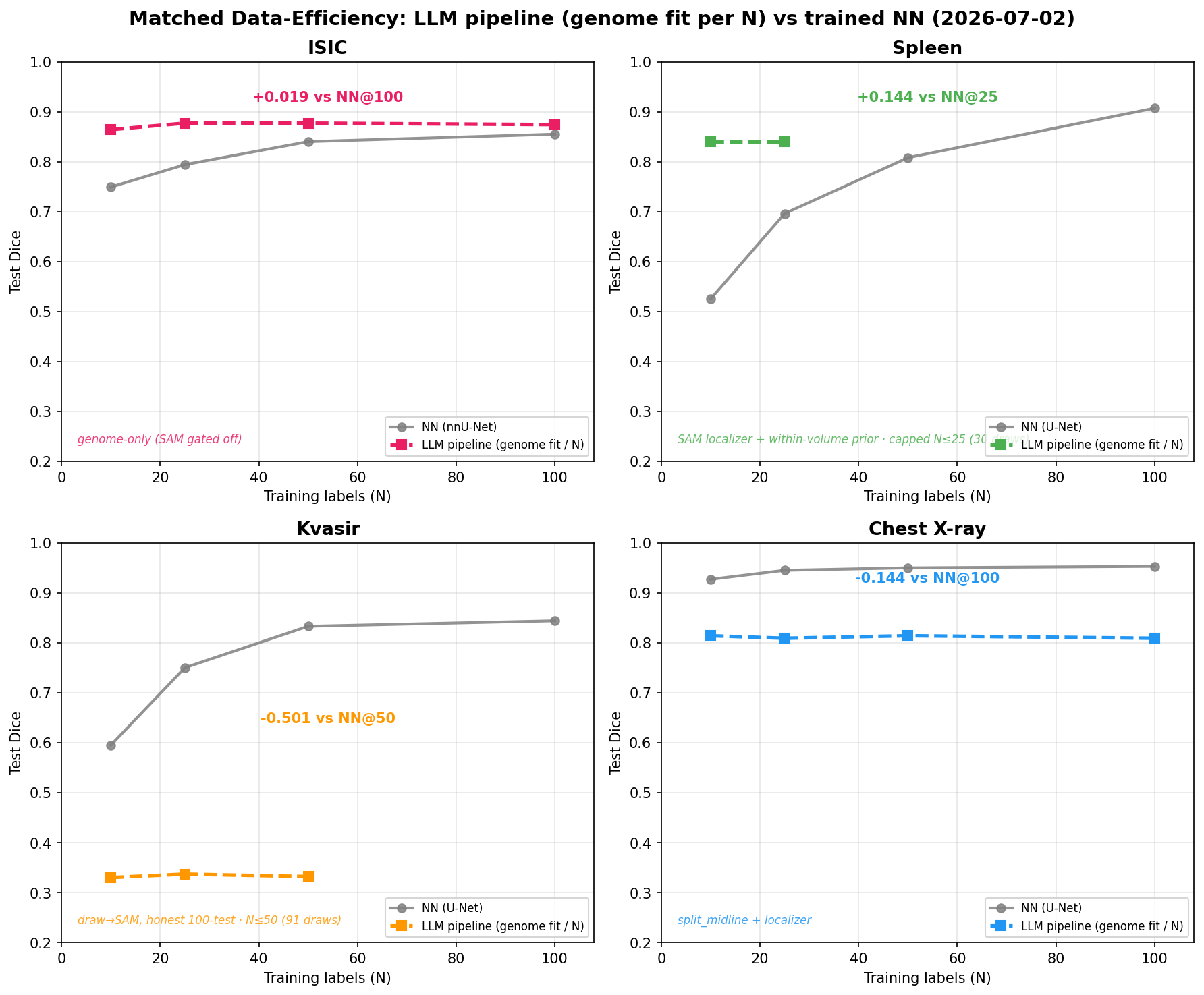
Is the residual to the trained NN a decoder limit or a localization limit? MedSAM (SAM fine-tuned on ~1M medical masks) beats box-prompted SAM — but it is data-leaky (its training set likely includes these test distributions), so it is really "import a trained medical net." The fair, leak-free counterpart of the same operation: init from the generic SAM (no medical data), freeze the image + prompt encoders, and fine-tune only the ~4M-param mask decoder on our own N-label train split — GT never touches test. Given a good box (the GT-box oracle, which isolates the decoder), this few-shot-tuned decoder beats the from-scratch NN at every budget on 4 of 5 domains (ISIC/Spleen/Kvasir/Prostate — Prostate by +0.12) and ties on the other one (CXR — a near-ceiling NN at ~0.95), and it saturates at N=10 (pretrained features + a tiny adapted head), so its curve is flat-high while the NN climbs:
| Domain (tuned decoder, oracle) | N=10 | N=25 | N=50 | N=100 | best NN N=100 |
|---|---|---|---|---|---|
| ISIC 2018 (derm) | 0.9047 | 0.9044 | 0.9071 | 0.9110 | 0.8544 |
| MSD Spleen (CT) | 0.9574 | 0.9602 | 0.9599 | 0.9528 | 0.9132 |
| Kvasir-SEG (endo) | 0.9360 | 0.9340 | 0.9372 | 0.9439 | 0.8643 |
| ChestXray (X-ray) | 0.9325 | 0.9462 | 0.9545 | 0.9556 | 0.9535 |
| MSD Prostate (MRI) | 0.9065 | 0.9311 | 0.9315 | 0.9377 | 0.8463 |
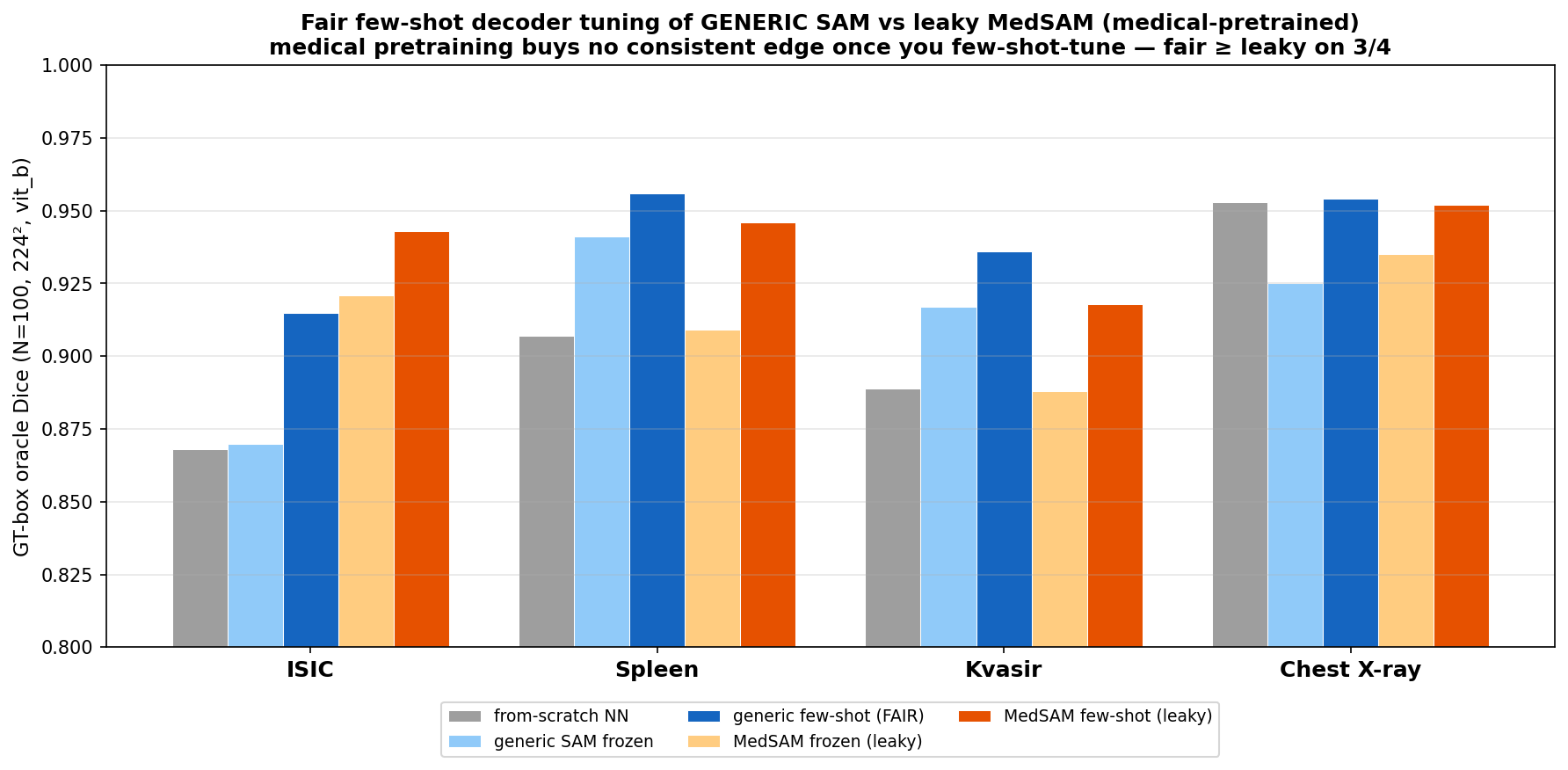
Is the medical pretraining (MedSAM) worth it? — a leaky benchmark
MedSAM is SAM already fine-tuned on ~1M medical masks — a leaky upper reference (its training likely saw these test distributions). Arch-matched (both vit_b, GT-box oracle, N=100), few-shot tuning of the GENERIC SAM matches or beats the leaky MedSAM on 3 of 5 domains, and stays within 0.015 on the other 2. This table preserves that experiment's arch-matched NN reference; the current strongest cached-NN grid is the data-efficiency section above.
| Domain (N=100 oracle, vit_b) | study NN reference | generic frozen | generic few-shot (fair) | MedSAM frozen (leaky) | MedSAM few-shot (leaky) |
|---|---|---|---|---|---|
| ISIC 2018 (derm) | 0.868 | 0.870 | 0.915 | 0.921 | 0.943 |
| MSD Spleen (CT) | 0.907 | 0.941 | 0.956 | 0.909 | 0.946 |
| Kvasir-SEG (endo) | 0.889 | 0.917 | 0.936 | 0.888 | 0.918 |
| ChestXray (X-ray) | 0.9546 | 0.925 | 0.954 | 0.935 | 0.952 |
| MSD Prostate (MRI) ·new | 0.815 | 0.895 | 0.928 | 0.807 | 0.941 |
ood_medsam.md). The oracle-box column above is a leaky upper reference. Give MedSAM a fair box (learned from N GT, not the oracle) and it drops +0.16..+0.59 Dice below the deployed pipeline in-distribution; take it out-of-distribution (DRIVE retinal vessels — a distribution MedSAM never trained on) and the gap widens to +0.51 while MedSAM collapses to 0.220 even handed the ORACLE box (vs ~0.90 in-distribution). MedSAM's in-distribution edge was its decoder recognizing box-shaped targets it had trained on — memorization that does not transfer; the pipeline's few-shot-refit GT-free localization is distribution-robust.How much of the framework transfers without domain-specific configuration?
The implementation shares operators and interfaces across domains, while drawer topology, supports, gates, and anatomical configuration remain validation-fitted per domain. The universal-harness control is therefore an ablation of manual configuration, not evidence of a fully autonomous universal segmenter.
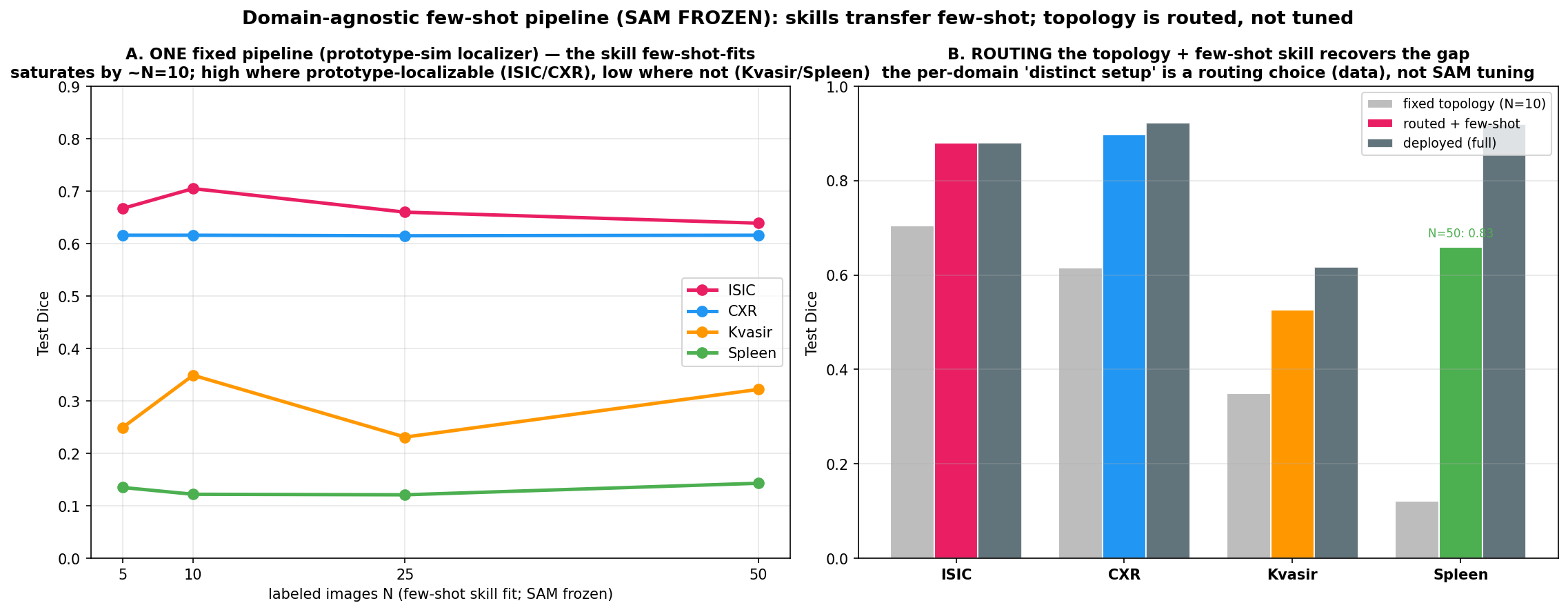
route.py), not SAM tuning. So onboarding a new domain is ~10 labels + a routing decision, zero gradient training. Robust localizer skill: the deployed default is now the op_sam frozen-DINOv2 dense-correspondence localizer (kvasir/prostate) — it transfers 10-shot support masks through the full patch cross-correlation, and superseded the earlier SAM+DINOv2 AMG-ranker ensemble on Kvasir (0.655→0.8646). The lesson holds and is now stronger: the polyp/fold wall yields to the right frozen feature space — dense correspondence, plus feature-diverse supports — not to distractor-verification tricks. The AMG-ranker ensemble (at/near the best single feature space on all three, Kvasir 0.65 / Spleen 0.64 / ISIC 0.67, never catastrophic where SAM-alone fails the isodense spleen 0.40) remains the LLM-agnostic fallback where a support set is too small for correspondence.